
Medicalrecruitersusa
Add a review FollowOverview
-
Founded Date December 8, 1948
-
Sectors test
-
Posted Jobs 0
-
Viewed 68
Company Description
Run DeepSeek R1 Locally – with all 671 Billion Parameters
Last week, I revealed how to easily run distilled variations of the DeepSeek R1 design in your area. A distilled design is a compressed variation of a bigger language design, where knowledge from a larger model is transferred to a smaller one to decrease resource use without losing excessive efficiency. These designs are based upon the Llama and Qwen architectures and be available in variations ranging from 1.5 to 70 billion criteria.
Some explained that this is not the REAL DeepSeek R1 which it is impossible to run the complete design in your area without a number of hundred GB of memory. That seemed like a difficulty – I thought! First Attempt – Heating Up with a 1.58 bit Quantized Version of DeepSeek R1 671b in Ollama.cpp

The developers behind Unsloth dynamically quantized DeepSeek R1 so that it could work on as little as 130GB while still gaining from all 671 billion criteria.
A quantized LLM is a LLM whose criteria are saved in lower-precision formats (e.g., 8-bit or 4-bit rather of 16-bit). This substantially lowers memory usage and speeds up processing, with very little effect on efficiency. The complete version of DeepSeek R1 utilizes 16 bit.
The compromise in precision is ideally compensated by increased speed.
I downloaded the files from this collection on Hugging Face and ran the following command with Llama.cpp.
The following table from Unsloth reveals the recommended value for the n-gpu-layers parameter, which shows how much work can be unloaded to the GPU.
According to the table, I thought 7 ought to be the optimum, however I got it running with 12. According to Windows Task Manager my GPU has 40 GB of memory, and not 24 as I thought. So then it builds up (7/ 24 * 40 ≈ 12).
If you prefer to run the design straight with Ollama, you must combine the three GGUF files utilizing Llama.cpp or a similar tool initially.
Above is some of the text that appears on screen while running the command.
Llama.cpp and the quantized design are heavy on memory and CPU, but likewise utilize the GPU (a little) and continuously check out from the disk where the design files are kept.
The model duplicates the concern and is getting ready to begin reasoning.
The reasoning, asteroidsathome.net or thinking, is rather lengthy – which likewise contributes to the total time it takes.
Okay, so I require to find out Alan Turing’s most essential contribution to how we live our lives in 2025. Hmm. Let’s start by remembering who Alan Turing was. He was a British mathematician and computer scientist, right? He’s known for his operate in code-breaking during World War II, particularly with the Enigma device. Oh, and he’s also considered among the dads of theoretical computer technology and artificial intelligence.

So, his contributions … Well, the Turing Machine idea is basic in computer system science. It’s a theoretical design of a computer, which laid the groundwork for contemporary computing. Then there’s the Turing Test, which is about identifying whether a device can exhibit intelligent behavior indistinguishable from a human. That relates to AI. Also, his deal with morphogenesis, which I think is about biological patterns and development, like how organisms establish shapes and patterns.
Now, how do these contributions impact life in 2025? Well, we remain in a world where AI is becoming more prevalent. So maybe his work on the Turing Test is influencing how AI is established and incorporated into society. If the Turing Test is a criteria for AI intelligence, then developments in AI that pass this test may be considerable. But wait, the Turing Test is more of a philosophical criteria. Maybe the actual algorithms or principles he established are more foundational.
The Turing Machine model is the basis for the stored-program computer system, which is the architecture of modern computers. All our computer systems today, consisting of smart devices, servers, and so on, are based upon this concept. So, in 2025, even as innovation advances, the essential concepts he laid down would still be the basis for all computational devices. That’s pretty big. Without that, we wouldn’t have the computers that power whatever from the internet to AI algorithms.
Additionally, his deal with code-breaking during WWII caused developments in cryptography. Modern file encryption methods might have roots in his work, which is necessary for protected interaction in 2025. Everything from online banking to personal messaging relies on file encryption, so that’s a huge contribution.
Another angle is his influence on the development of algorithms. The idea of a universal computing maker permits the creation of complex algorithms that drive AI, information analysis, artificial intelligence, etc. So, any AI systems in 2025 would originate from his foundational work.
Also, morphogenesis may have affected fields like biology and genetics. Maybe in 2025, understanding biological patterns assists in locations like genetic engineering or artificial biology. But I’m uncertain how straight that ties into daily life compared to computing.
Putting it all together, the most crucial contribution may be the Turing Machine and the theory of calculation, which underpin all contemporary computing innovation. Without that, the digital age would not exist as we understand it. In 2025, even with improvements, the basic framework of calculation he provided would still be important. Alternatively, his deal with AI and the Turing Test may be more highlighted in an AI-driven future, but the foundational computing theory seems more essential.
Wait, but the Turing Test is more about examining AI rather than a contribution to innovation itself. The real contribution is the theoretical basis for computing, which allowed all the digital tech we have. So, in 2025, all the wise gadgets, AI, cloud computing, and so on, are all built on the principles he established. Therefore, his essential contribution is the concept of a universal Turing maker, which is the basis for all contemporary computers, resulting in the digital transformation that specifies contemporary life.
And finally the answer.
Alan Turing’s most considerable contribution to how we live in 2025 is his fundamental operate in theoretical computer system science, particularly the idea of the universal Turing maker. This theoretical design developed the concepts of contemporary computation, forming the basis for all digital computers. In 2025, this development underpins the entire digital world, making it possible for innovations like expert system, cloud computing, mobile phones, and the internet. Without Turing’s conceptual structure, the advancement of programmable computer systems and subsequent technologies that define modern life-from AI algorithms to protect communication systems-would not have actually been possible. His work on cryptography and the Turing Test also contributed to secure interactions and AI development, but it is the universal Turing maker that remains the cornerstone of our digital presence.
In summary: The 1.58 bit quantized model produced 0.39 tokens per second. In overall, it took about 37 minutes to answer the exact same concern.
I was kind of surprised that I was able to run the design with only 32GB of RAM.
Second Attempt – DeepSeek R1 671b in Ollama
Ok, I get it, a quantized model of just 130GB isn’t actually the full model. Ollama’s model library seem to include a full variation of DeepSeek R1. It’s 404GB with all 671 billion specifications – that should be real enough, right?
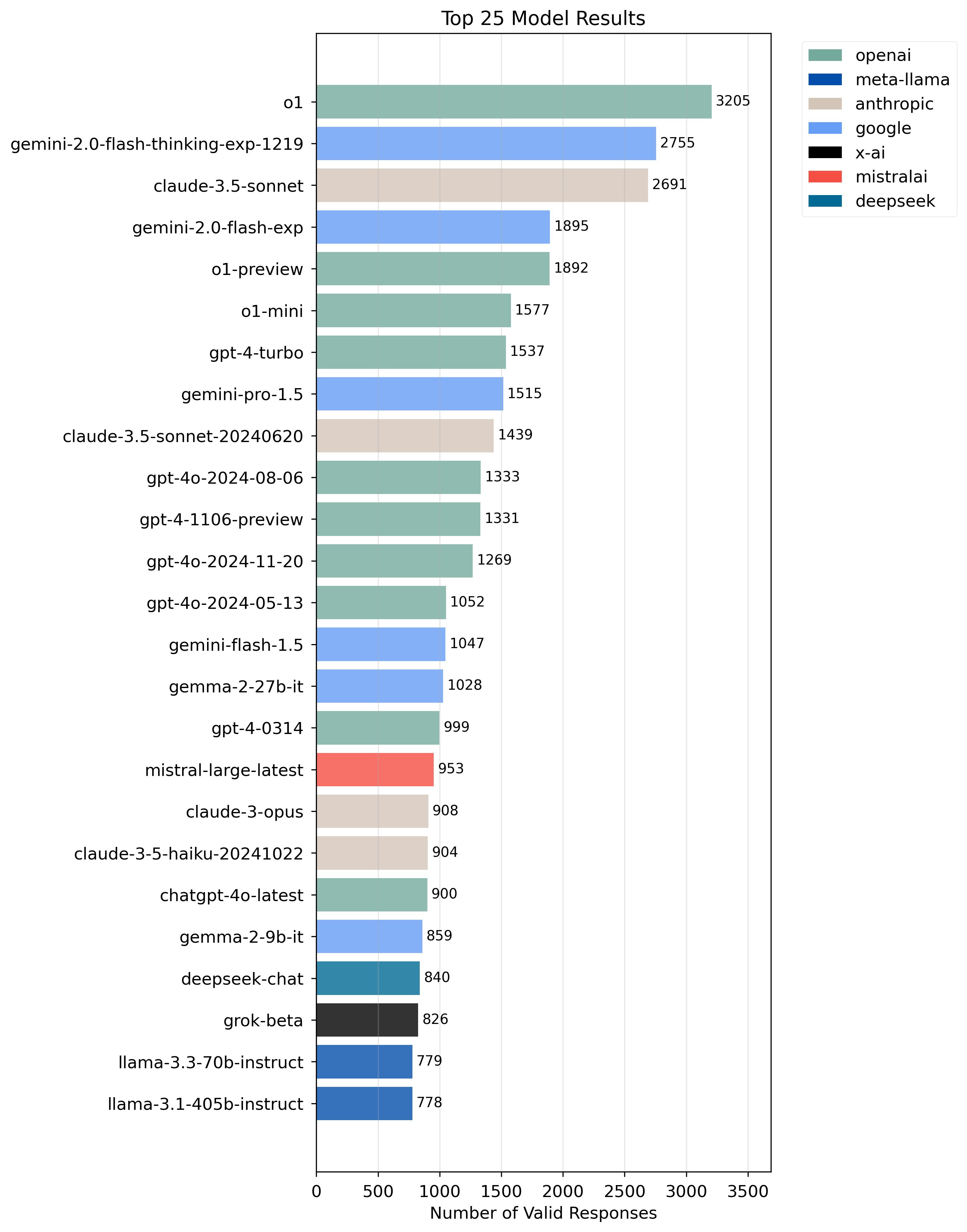
No, not actually! The version hosted in Ollamas library is the 4 bit quantized variation. See Q4_K_M in the screenshot above? It took me a while!
With Ollama set up on my home PC, I simply needed to clear 404GB of disk area and run the following command while getting a cup of coffee:
Okay, it took more than one coffee before the download was total.
But lastly, the download was done, and the enjoyment grew … up until this message appeared!
![]()
After a quick visit to an online store selling different kinds of memory, I concluded that my motherboard would not support such big amounts of RAM anyway. But there must be options?
Windows permits virtual memory, indicating you can swap disk space for virtual (and rather slow) memory. I figured 450GB of additional virtual memory, in addition to my 32GB of genuine RAM, should be adequate.
Note: Understand that SSDs have a minimal variety of write operations per memory cell before they wear. Avoid excessive use of virtual memory if this concerns you.
A new effort, and rising excitement … before another mistake message!
This time, Ollama tried to push more of the Chinese language design into the GPU’s memory than it might manage. After browsing online, it seems this is a known issue, however the service is to let the GPU rest and let the CPU do all the work.
Ollama uses a “Modelfile” containing setup for the design and how it ought to be used. When utilizing models straight from Ollama’s model library, you normally do not deal with these files as you should when downloading models from Hugging Face or comparable sources.
I ran the following command to display the existing configuration for DeepSeek R1:
Then, I added the following line to the output and waited in a new file named Modelfile:
I then produced a brand-new design configuration with the following command, where the last specification is my name for the model, which now runs completely without GPU use:
Once again, the excitement grew as I nervously typed the following command:
Suddenly, it occurred! No error message, but tokens started appearing! Admittedly, the speed was such that if you were quick enough, you could almost get a coffee in between each screen update – however it was working! A language model on par with the finest from OpenAI, with all its 671 billion specifications, operating on my three-year-old PC with 32GB (genuine) RAM!
I had asked the exact same question to both ChatGPT (4o, o1, 03-mini-high), DeepSeek R1 hosted in China and DeepSeek R1 671b hosted locally.
This is the thinking from DeepSeek R1 running in Ollama on my own computer system, as it appeared slowly-token by token.
And lastly this is the response from DeepSeek R1 running in Ollama. The model outputs the response with markdown format.

Alan Turing’s most substantial contribution to modern life, particularly as we look toward 2025, lies in his foundational work on computational theory and synthetic intelligence, which underpin nearly every element of modern-day innovation. Here’s a structured breakdown:
1. Universal Turing Machine (1936 ):
– This conceptual design for general-purpose computing is the bedrock of all digital technology today. It developed that a single device could carry out any computable task with the right program, making it possible for: Modern Computing Devices (mobile phones, cloud infrastructure, IoT).
Software Development, permitting flexible applications across markets.
2. In 2025, improvements in quantum computing, AI, and edge computing still rely on Turing’s concepts of programmable reasoning.
3. Artificial Intelligence & the Turing Test (1950 ):
– His structure for assessing maker intelligence stimulated years of research study into human-like AI. By 2025, this tradition appears in: – Advanced chatbots, virtual assistants (e.g., GPT-4/ 5), higgledy-piggledy.xyz and self-governing systems.
– Ethical debates around AI decision-making in health care, finance, and law.
4. Cryptography & Security:
– Turing’s WWII codebreaking work foreshadowed modern-day encryption strategies important for: – Securing digital transactions, individual information, and blockchain innovations.
– Combating cyber hazards in an increasingly connected world.
Why the Universal Machine Sticks Out: While AI and cryptography are transformative, Turing’s theoretical model of computation is the most basic. It allowed the production of programmable systems that drive today’s innovations-from AI algorithms to quantum computing research. Without this structure, the digital infrastructure of 2025 simply would not exist.
So, for how long did it take, using the 4 bit quantized model? A long time! At 0.05 tokens per second – implying 20 seconds per token – it took almost 7 hours to get an answer to my concern, including 35 minutes to pack the model.
While the model was believing, the CPU, memory, and the disk (used as virtual memory) were close to 100% hectic. The disk where the design file was conserved was not busy throughout generation of the response.

After some reflection, I believed possibly it’s alright to wait a bit? Maybe we should not ask language models about everything all the time? Perhaps we need to think for ourselves first and be ready to wait for an answer.
This might resemble how computers were utilized in the 1960s when devices were large and availability was . You prepared your program on a stack of punch cards, which an operator packed into the maker when it was your turn, and you might (if you were fortunate) get the result the next day – unless there was an error in your program.
Compared with the response from other LLMs with and without thinking

DeepSeek R1, hosted in China, believes for 27 seconds before providing this response, which is slightly much shorter than my in your area hosted DeepSeek R1’s action.
ChatGPT answers likewise to DeepSeek but in a much shorter format, with each model supplying somewhat various reactions. The thinking designs from OpenAI spend less time thinking than DeepSeek.
That’s it – it’s certainly possible to run different quantized versions of DeepSeek R1 locally, with all 671 billion parameters – on a three year old computer system with 32GB of RAM – just as long as you’re not in too much of a rush!
If you actually desire the complete, non-quantized variation of DeepSeek R1 you can discover it at Hugging Face. Please let me understand your tokens/s (or rather seconds/token) or you get it running!